

When you build Software as a Medical Device, you are permanently navigating four forces that pull against each other simultaneously: you need to ship fast because the company depends on it, you cannot cut compliance corners because the regulator will find them (and so will patients), you need to engineer the data layer in a way that makes it genuinely useful once real-world data begins to accumulate, and you need to do all of this without creating another silo that future teams will inherit and curse.
In our experience, most organisations try to solve these forces one at a time: speed first, compliance retrofitted, analytics bolted on later, integration deferred to the next version. We know this pattern well, having followed it ourselves more than once, to consistently poor effect. This is why we built the data layer first.
The Retrofit Problem
The compliance retrofit is the most expensive mistake you can make in medical device software, and it is particularly insidious because it looks entirely manageable at the time it is being made: the product is working, the team is moving fast, and the data schema is “good enough for now,” with classification and data protection deferred to just before regulatory submission under the comfortable assumption that there will always be time for it later. An assumption that turns out, without exception, to be wrong.
By the time you return to the data layer, it has been built upon by other services that now depend on its original form, the schema has been interpreted a dozen different ways by developers working under different assumptions, fields that should have been encrypted are stored in plaintext because a dashboard needed them readable at some point, a patient identifier that should have been pseudonymised is sitting in five different tables in its raw form, the audit trail was never wired to the write path, and the data that should be driving post-market surveillance is scattered across collections with no consistent classification. We have been in those codebases, and we have been responsible for some of them.
The Insight Problem Is Downstream of the Governance Problem
There is a temptation to treat data access and data insights as separate concerns (the data layer as infrastructure, analytics as a product decision for later) and this is another expensive misconception.
The moment you have real patients using your device, you need to be able to ask questions of the data: how is this population responding, are certain subgroups behaving differently, is there a signal we should be tracking. These are not post-market questions but active product questions that arise within weeks of launch. If the data layer was not designed for this, your team will spend months preparing datasets before anyone can run a single query, writing one-off export scripts, arguing about what a field means, and discovering that the same concept is stored three different ways depending on which version of the schema was active, so that the data that should produce insight produces meetings instead.
And if your data is locked in a proprietary schema with no coherent governance model, it will not connect to anything else in your ecosystem, ensuring that the next product you build starts from scratch and generates a new silo alongside the old one.
What We Arrived At
After years of building regulated software, and fixing what we had broken, we arrived at a simple conviction: governance cannot be added to a data layer, because it has to be the data layer.
The H.Core Data Orchestration Layer is the result of that conviction: every field in every entity must carry an explicit classification before it can be stored, and that classification is not metadata in a document but an executable contract enforced on every read and every write, so that the platform decides what protection to apply, what transformations to perform, and what audit events to emit, while the developer defines only the intent and the platform enforces the obligation.
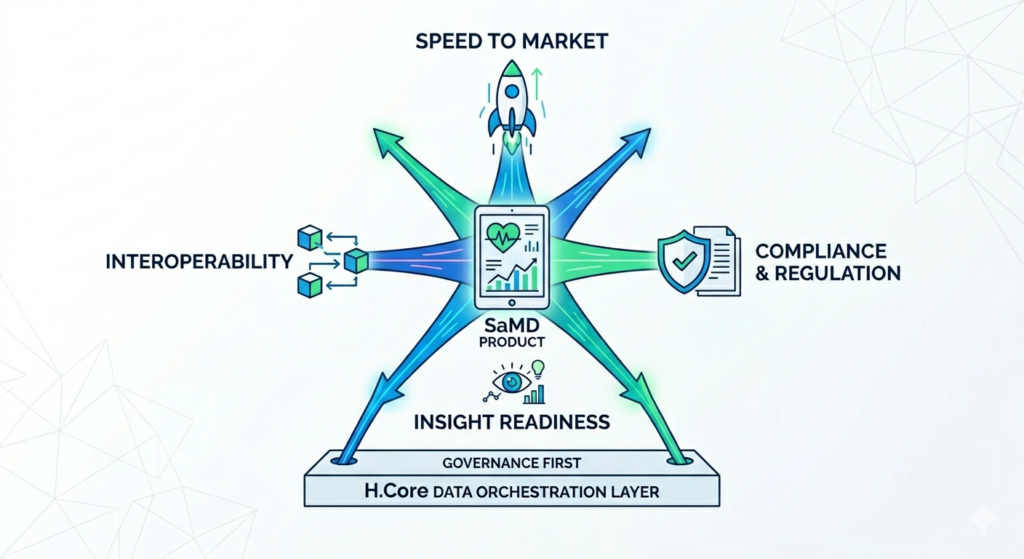
This means that a team building a new product does not face a compliance debt accumulating with every sprint, and that the data entering the system is, from day one, in a form that can be queried, analysed, and connected to other governed entities, because every entity in the registry is already classified, protected, and auditable by construction. When patients start using the device and data begins to accumulate, the insight infrastructure is already in place, not because someone planned ahead heroically, but because the platform made it the default.
We did not design this system because we read about data fabric architecture, but because we spent years learning, the hard way, what happens when you do not.
The four forces (speed, compliance, insight readiness, and interoperability) are not actually in conflict if you address them at the right layer. They only conflict when you try to satisfy them one at a time, in the order that feels most urgent. Governance first is not a constraint, but the only path that keeps all four forces in balance.
H.Core is the adaptive SaMD development platform built by Newel Health. The H.Core Data Orchestration Layer is the governed data foundation of the platform. Get in touch to learn how we handle data compliance by construction.